12 Fork-Join Framework
12.1 “Fork-Join” Entwurfsmuster
“Fork-Join” ist ein generelles Entwurfsmuster für parallele Programmierung, das eine gewisse Lösungsstrategie für Parallelität beschreibt. Das Fork-Join Framework ist eine wiederverwendbare Umsetzung in Java, die Teil der Java Standard Library ist.
Für dieses Entwurfsmuster gibt es auch in anderen Programmiersprachen Umsetzungen, bspw. in der C++-Library Boost1
12.1.1 Kontrollfluss beim Entwurfsmuster “Fork-Join”
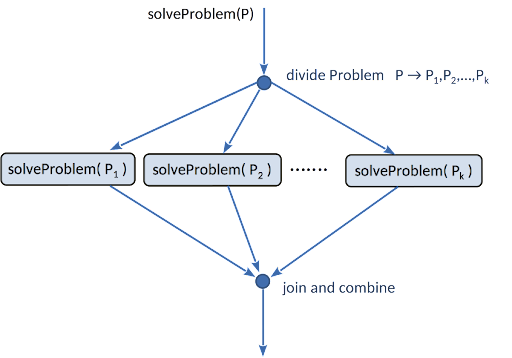
- Der Kontrollfluss wird an einer Stelle in mehrere nebenläufige Flüsse aufgeteilt (“fork”), die an einer späteren Stelle alle wieder vereint (“join”) werden.
- Dies ist immer dann anwendbar, wenn ein komplexes Problem in kleinere gleichartige Teilprobleme zerlegt werden kann, die unabhängig voneinander und damit potenziell parallel gelöst werden können.
- Die Lösungen der Teilprobleme können dann zur Gesamtlösung kombiniert werden.
12.1.2 Rekursive Verwendung
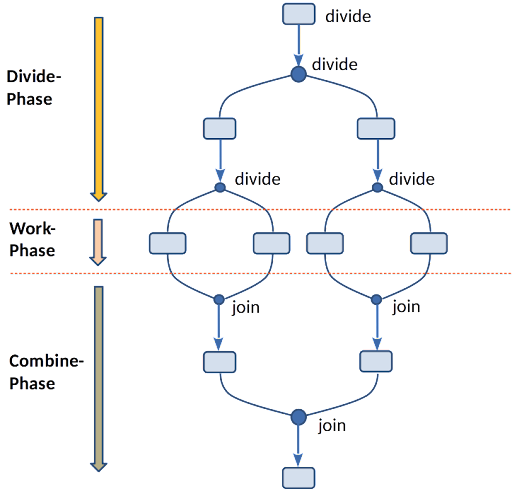
- Dies ist besonders geeignet für rekursive Algorithmen (“Divide and Conquer”):
- In der ersten Phase wird das Problem immer wieder zerkleinert (Divide-Phase).
- Ist eine entsprechende Problemgröße erreicht, werden die Teilaufgaben gelöst (Work-Phase) und
- anschließend das Ergebnis zusammengesetzt (Combine-Phase).
12.2 Programmiermodell des Fork-Join Frameworks
12.2.1 ForkJoinPool und “Work-Stealing” im Threadpool
ForkJoinPool (seit Java 7) implementiert ExecutorService:
- Ein Standard-Pool ist bereits instanziiert:
ForkJoinPool.commonPool()(seit Java 8) - “Using the common pool normally reduces resource usage (its threads are slowly reclaimed during periods of non-use, and reinstated upon subsequent use)”2
- Parallelität wird im Konstruktor vorgegeben
- Default-Wert:
Runtime.getRuntime().availableProcessors()(max.32767)
- Default-Wert:
- Eigener Scheduler: Alle Threads im Pool versuchen anstehende Subtasks zu finden und zu übernehmen, die von anderen aktiven Tasks erzeugt wurden (“Work-Stealing”).
- Threads, die keine Aufgaben mehr zu erledigen haben, können Aufgaben von anderen Threads übernehmen (“stehlen”), die gerade beschäftigt sind.
- Aufgaben werden in Queues gespeichert.
- Effiziente Verarbeitung, wenn die meisten Tasks Subtasks erzeugen.
12.2.2 Programmiermodell
ForkJoinTask<E>: leichtgewichtigesFuture<E>(soll nicht blockieren)RecursiveAction: Kein Rückgabewert (nur Seiteneffekt, z.B. bei in-place/in situ3 Sortierung)RecursiveTask<E>: Funktion mit Rückgabewert (wird z. B. vom “Über-Task” mitjoin()geholt und in Ergebnis eingebaut)

Achtung: Fehler im Buch Hettel und Tran (2016): RecursiveAction ist kein generischer Typ (extends ForkJoinTask<Void>).
12.2.2.1 Implementieren der Funktionalität
- durch Überschreiben der Methode
protected abstract void compute()vonRecursiveActionundprotected abstract E compute()vonRecursiveTask<E>
12.2.2.1.1 Anforderungen an ForkJoinTasks
- kein (oder nur seltenes) Blockieren (durch
synchronized, locks, I/O, etc.) - Annäherung: keine Checked Exceptions (z. B.
IOException) return(Join) “von innen nach außen”:
12.2.2.1.2 Optimaler Durchsatz durch Parallelisierung
ForkJoinTask::computesollte relativ kleine Berechnungen durchführen- größere Aufgaben zuerst in kleinere Chunks aufteilen
- Heuristik: 100-10000 Rechenschritte pro Task (Overhead bei kleineren Tasks zu groß)
12.2.3 Ausführungsmodell
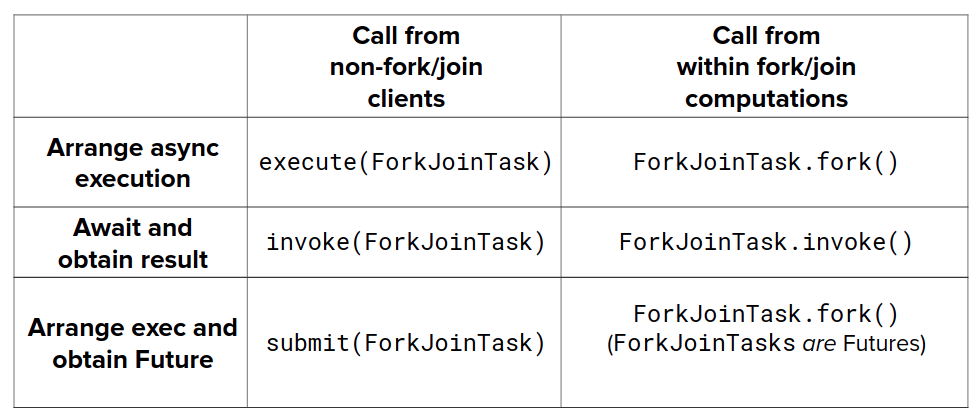
invokeAll(...)fürinvoke(...)auf alle Elemente einerCollection<ForkJoinTask>- “Call from non-fork/join clients”
- Methode wird an
ForkJoinPool-Instanz mitForkJoinTaskals Parameter aufgerufen (z. B. bei erstem Aufruf in die Rekursion)
- Methode wird an
- “Call from within fork/join computations”
- Methode wird an
ForkJoinTaskaufgerufen (es handelt sich dann um einen Sub-Task, der aus der Aufspaltung einer “Über-Aufgabe” entstanden ist)
- Methode wird an