4 Threadpools und asynchrone Methodenaufrufe
4.1 Threads, die ein Ergebnis berechnen
4.1.1 Asynchroner Funktionsaufruf für “Data Flow”-Aufgaben
Der Begriff “Data Flow” bedeutet im Zusammenhang mit Nebenläufigkeit, dass größere Probleme in Teilaufgaben zerlegt werden, die uanbhängig voneinander gelöst werden können. Die Berechnung der Teilergebnisse kann in einem verteilten System erfolgen oder in einem nebenläufigen Programm. Die “Bewegung” der Teilergebnisse in einem gedachten oder realen Netzwerk aus voneinander abhängigen Berechnungsschritten auf dem Weg zum Gesamtergebnis stellt einen “Datenfluss” dar.
Der Operator ; bedeutet “sequentielle Ausführung der beiden Operanden” (zuerst der linke, danach der rechte). Der Operator || bedeutet, dass die Reihenfolge der Ausführung der beiden Operanden egal ist und dass beide parallel oder überlappend berechnet werden dürfen. Diese Notation wurde zuerst von Sir Charles Antony Richard (“Tony”) Hoare zur Beschreibung des Konzepts “Communicating Sequential Processes” verwendet (Hoare (1978)).
Reihenfolgen, in der die Ausdrücke berechnet werden können:
- sequentiell
- \(1+2\)
;\(3+4\);\(3+7\) - \(3+4\)
;\(1+2\);\(3+7\)
- \(1+2\)
- parallelisiert
- \(1+2\)
||\(3+4\);3+7
- \(1+2\)
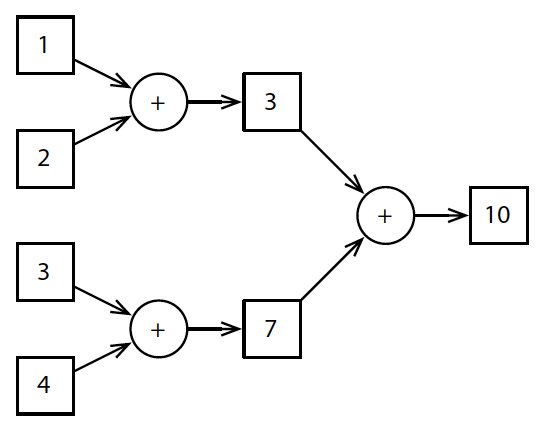
Die Berechnung der beiden Ausdrücke \(1+2\) und \(3+4\) ist unabhängig voneinander. Sie können parallel ausgeführt werden. Die Berechnung eines Ausdrucks führt zu einem Ergebnis. Die Berechnung des Ausdrucks \(3+7\) ist abhängig von den Ergebnissen der beiden anderen Ausdrücke. Sie kann erst begonnen werden, wenn die Ergebnisse beider Ausdrücke vorliegen.
4.2 ExecutorService für asynchrone Methodenaufrufe: Callable und Future
4.2.1 Problemstellung: asynchroner Methodenaufruf
Wie kann ein nebenläufiger Thread ein Ergebnis abliefern?
- Die einzige Aufgabe solch eines Threads ist, genau eine (ggf. langdauernde) Berechnung durchführen.
- Die Berechnung soll nebenläufig ablaufen: Nach dem Start geht es direkt im Programmfluss des Erzeugers weiter.
- Man weiß nicht, wie lange der Thread für die Berechnung braucht. Eine Schnittstelle ist deshalb erforderlich um zu prüfen, ob das Ergebnis schon vorliegt.
- Bei der Berechnung könnten Exceptions geworfen werden. Die sollen nicht asynchron durchgereicht werden.
4.2.2 Callable und Future
- Asynchrone Verarbeitung wird in Java mit
Callable,RunnableundFuturegemacht. CallableundRunnablerepräsentieren die asynchron abzuarbeitende Aufgabe.- Mit
Futurekann das Ergebnis einer asynchronen Berechnung abgerufen werden (get()) FutureTaskist eine Implementierung vonFutureundRunnable.

4.2.2.1 Exkurs: Asynchrone Verarbeitung in anderen Programmiersprachen und Abgrenzung von Future und Promise1
In den Programmiersprachen Dart und C# gibt es die Schlüsselwörter async und await, mit denen eine asynchrone Verarbeitung gestartet werden kann.
Neben dem Begriff Future gibt es auch noch Promise. In JavaScript ist das bspw. der Typ, mit dem statt Future auf das Ergebnis eines asynchronen Aufrufs zugegriffen wird.
Achtung: Der Begriff Promise wird auch für Lazy Evaluation z.B. in Scheme verwendet, ohne dass asynchrone, nebenläufige Verarbeitung gemeint ist.
Die Konzepte hinter Promise und Future sind zwar sehr ähnlich, es gibt aber einen Unterschied: Future-Objekte sind “read-only”. Futures sind nur dazu da, das Ergebnis der Berechnung als Container zu halten und bereitzustellen. Die Methode set von FutureTask, einer Implementierung von Future, hat die Sichtbarkeit protected. Der Wert eines FutureTasks kann also nur aus dem java.util.concurrent-Package heraus gesetzt werden.
Bei Promises kann das darin repräsentierte Ergebnis geschrieben werden (wenn auch normalerweise nur einmal). Dies ermöglicht es, eine Verkettung von asynchronen Aufrufen zu machen (Promise-Pipelining aus JavaScript (.then)). In Java gibt es das auch, heißt hier aber nicht Promise, sondern CompletableFuture. Das CompletableFuture-Framework wird im übernächsten Kapitel ausführlich dargestellt.
4.2.3 ExecutorService-Framework
- Die asynchrone Verarbeitung erfolgt in Java durch
ExecutorService. - Implementierungen nehmen über die Methode
submitCallable-Objekte an und startencall()asynchron. - Als Ergebnis bekommt der Aufrufer ein
Futureals Proxy, über den- auf das Ergebnis zugegriffen wird
- die asynchrone Berechnung gemanagt wird

4.2.4 Callable asynchron mit ExecutorService ausführen
Im folgenden Hauptprogramm (Main) gibt es ein Objekt, dessen Klasse das ExecutorService-Interface implementiert. Wie das genau erzeugt wird, kommt im nächsten Abschnitt.
Der ExecutorService verwaltet mindestens einen Thread.

Zuerst wird hier aus Main ein Callable-Objekt (c) erzeugt. Im Beispiel geschieht dies durch die Anwendung einer anonymen inneren Klasse. V ist dabei ein Typ-Parameter, der dem Typ des Rückgabewertes von call entspricht.
Das Callable c wird dann aus dem Hauptprogramm heraus dem ExecutorService mit submit übergeben. Der Aufruf von submit hat ein Objekt zum Ergebnis dessen Klasse das Interface Future<V> implementiert. Im Sequenz-Diagramm ist angegeben, dass für f die Klasse FutureTask<V> benutzt wird. Die Wahl der Future-Implementierung ist jedoch dem ExecutorService überlassen.
Das Future wird vom ExecutorService erzeugt und verwaltet. Es wird (auf den folgenden Folien) verwendet, um mit dem Callable bzw. dem Thread, in dem das Callable ausgeführt wird, zu interagieren.
Wichtig ist aber, dass der Aufruf von submit den Main-Thread nur kurzzeitig blockiert. Die Rückgabe von f ist unabhängig von der Berechnung von call() in c. Die Ausführung im Thread ist nebenläufig zum Rest. Das soll in diesem Sequenzdiagramm durch die beiden Farben grün und blau der Lifelines ausgedrückt werden.
Der ExecutorService sorgt dafür, dass das Callable “in den Thread t geladen wird”. An dieser Stelle gehen wir nicht weiter in die Tiefe, wie das genau funktioniert, sondern nehmen als Abstraktion, dass t mitgeteilt wird, dass das Callable c auszuführen ist und dass f zur Interaktion mit t bzw. c verwendet wird.
Irgendwann später, also asynchron vom weiteren Ablauf des Hauptprogramms, startet der Thread in seinem nebenläufigen Programmfluss die Methode call() aus c. Ab hier wird call() dann tatsächlich nebenläufig bzw. asynchron vom restlichen Programmfluss ausgeführt.
c wird asynchron (nebenläufig in t) zum Hauptprogramm (bzw. zum Main-Thread) ausgeführt. Es kann erforderlich sein, aus dem Main-Thread heraus zu erfragen, ob die asynchrone Ausführung noch läuft oder beendet ist. Diese (und andere Interaktion) mit c bzw. t erfolgt über das Future f. Im gezeigten Beispiel wird die Methode isDone() an f aufgerufen. f kennt den Bearbeitungsstand von c (warum folgt auf der nächsten Folie) und kann false zurückliefern, falls die Berechnung von call() andauert.
Da die Berechnung von call() in c asynchron vom Hauptprogramm erfolgt, muss auf einem besonderen Weg auf den Rückgabewert von call() zugegriffen werden: Dafür ist das Future f da. An ihm kann die Methode get() aufgerufen werden. Der Aufruf von get() blockiert aus Sicht von Main bis ein Ergebnis von f zurückgegeben wird. Das kann erst passieren, wenn call() fertig berechnet ist und die asynchrone Ausführung endet. Sollte das Ergebnis von call() bereits vorliegen, wenn get() aufgerufen wird, blockiert der Aufruf von get() nicht.
Wenn call() fertig berechnet ist, wird das Ergebnis (hier v vom Typ V, also dem Typ-Parameter des Callable und des FutureTask) zurückgeliefert. Wir beim eigentlichen Start von call() in t abstrahieren wir hier von den tatsächlichen Vorgängen.
t sorgt aber im Ergebnis dafür, dass v im FutureTask als Resultat gesetzt wird.
Im dargstellten Fall wartet Main durch den blockierten Aufruf von get() darauf, dass ein Ergebnis bereitgestellt wird, was auch passiert, nachdem set(v) bei f aufgerufen worden ist.
4.3 Thread Pools
4.3.1 Warum Thread Pools?
Thread-Instanziierung ist “teurer” (dauert länger) als bei anderen Klassen, denn Datenstrukturen zur Threadkontrolle müssen angelegt werden und threadlokaler Stack-Speicher angefordert werden.- Optimierung:
Thread-Objekte werden frühzeitig (z.B. beim Start) vorbereitet (“Thread Pool”). Wird ein Thread benötigt, wird einer der vorbereiteten Threads aus dem Pool genommen, mit einemRunnable-Objekt verbunden und (re-) aktiviert (stattstart()). - Beim Ende der
run()-Methode wird der Thread nicht vergessen und über die Garbage Collection entfernt, sondern deaktiviert und in den Thread Pool zur Wiederverwendung eingestellt.
4.3.2 ExecutorService-Framework
Die Klasse Executors stellt Factory-Methoden zur Erzeugung von Objekten zum ExecutorService-Interface bereit:
newCachedThreadPool()newFixedThreadPool(nThreads: int)newSingleThreadExecutor()

4.3.3 Shutdown eines Thread Pools
shutdown()- Die bereits eingestellten Aufgaben werden noch abgearbeitet, neue werden zurückgewiesen.
- Der
ExecutorServicebeginnt, herunterzufahren. Der Aufruf vonshutdown()ist aber asynchron (es geht direkt im Anschluss weiter im Programmablauf.
isShutdown()- prüfen, ob der
ExecutorServicebereits fertig terminiert ist (nachshutdown()).
- prüfen, ob der
shutdownNow()- Erzwingen der sofortigen Terminierung der Threads im
ExecutorService: Alle aktiven Tasks erhalten mitinterrupt().
- Erzwingen der sofortigen Terminierung der Threads im
4.3.4 Das ExecutorService-Framework
Hier wird zuerst ein neuer Thread Pool erzeugt. In diesem Beispiel ist das ein Fixed Thread Pool der Größe 5. Er beinhaltet also 5 Threads, die zum Zeitpunkt der Instanziierung des Thread Pools erzeugt werden. Der Thread Pool implementiert (wie alle Thread Pools) das Interface ExecutorService.
In diesem Thread Pool werden dann mit submit 100 Tasks gestartet. Der Parameter von submit ist normalerweise vom Typ Callable. submit ist aber überladen und es gibt auch eine Variante mit dem Typ Runnable als Parameter. Und tatsächlich hat der hier verwendete Lambda-Ausdruck keine Rückgabe. Er implementiert also das Interface Runnable.
Das Runnable wird 100 x im Thread Pool gestartet. Dort stehen aber nur 5 Threads zur Verfügung, die wiederverwendet werden, wenn die jeweils ausgeführte Aufgabe beendet ist. Die Ausgabe des Threadnamens dauert nicht sehr lang, so dass die Threads gleich wieder benutzt werden können. In der Ausgabe sollte sich zeigen, dass derselbe Thread (z.B. pool-1-thread-4) mehrmals (z.B. \(100/5=20\) mal) zur nebenläufigen Abarbeitung der Aufgabe aus dem Lambda-Ausdruck verwendet wurde.
Da es sich um einen Fixed Thread Pool handelt, bleiben die Threads im RUNNABLE-Zustand, auch wenn gerade keine Aufgabe anliegt (dem Thread Pool mit submit übergeben wurde). Die Threads im Thread Pool sind also weiter aktiv, auch wenn die 100 Ausgaben getätigt wurden. Selbst wenn dies die einzige Aufgabe in der main-Methode wäre, terminiert die JVM deshalb nicht. Um das zu erreichen, muss der Thread Pool mit shutdown() “manuell” beendet werden.
Um zu untersuchen, wie sich unterschiedliche Thread Pools verhalten, kann hier der Typ des Thread Pools zu einem Cached Thread Pool geändert werden. Die Ausgaben sollten sich unterscheiden. Das Verhalten in Bezug auf das Terminieren sollte auch unterschiedlich sein.
Dieses Programm liefert beispielsweise folgende Ausgabe:
pool-1-thread-1
pool-1-thread-3
pool-1-thread-2
pool-1-thread-4
pool-1-thread-5
pool-1-thread-3
pool-1-thread-4
pool-1-thread-3
pool-1-thread-2
pool-1-thread-4
pool-1-thread-3
pool-1-thread-5
pool-1-thread-3
pool-1-thread-4
pool-1-thread-2
pool-1-thread-2
pool-1-thread-2
pool-1-thread-2
pool-1-thread-44.3.5 Thread Pool Framework von Java Executors Factory
4.3.5.1 Cached Thread Pool

erzeugt bei Bedarf neue Threads, unbenutzte Threads werden nach 60 Sekunden beendet
\(\to\) Programme mit kurzlebigen, asynchronen Aufgaben
4.3.5.2 Fixed Thread Pool

genau nThreads werden erzeugt, überzählige Runnables bzw. Callables werden in Queue gespeichert
\(\to\) Programme mit sehr vielen unabhängigen Aufgaben
4.3.5.3 Single Thread Pool

Sonderfall von newFixedThreadPool(1). Stürzt der Thread ab, wird er neu gestartet
\(\to\) Programme mit weniger unabhängigen Aufgaben; “Absturzsicherung”
4.3.5.4 Scheduled Thread Pool

Aufgaben werden nach einer gegebenen Verzögerung bzw. periodisch ausgeführt
\(\to\) Programme mit vielen zeitlogisch abhängigen Aufgaben
4.3.5.5 Single Scheduled Thread Pool

Sonderfall von newScheduledThreadPool(1). Stürzt der Thread ab, wird er neu gestartet
\(\to\) Programme mit einigen zeitlogisch abhängigen Aufgaben; “Absturzsicherung”
4.3.6 ScheduledExecutorService
- Das Interface
ScheduledExecutorServicebzw. dessen ImplementierungScheduledThread
PoolExecutorerlaubt Aufgaben in Form vonCallableundRunnable- zu bestimmten Zeiten oder
- wiederholt auszuführen.
- Auch dieser
ExecutorServicewird durch die FactoryExecutorerzeugt.

Dazu gibt es die Methoden:
schedulestarte einmalig in \(x\) ZeiteinheitenscheduleAtFixedRatewarte \(x\) Zeiteinheiten und starte dann periodisch alle \(y\) ZeiteinheitenscheduleWithFixedDelaywarte \(x\) Zeiteinheiten und starte dann, nach dem Ende des Tasks warte \(y\) Zeiteinheiten und starte erneut, …
4.3.6.1 Beispiel
var scheduler = Executors.newScheduledThreadPool(1);
var beeperHandle = scheduler.scheduleAtFixedRate(
() -> System.out.println("beep"), 3, 3, TimeUnit.SECONDS
);
scheduler.schedule(
() -> beeperHandle.cancel(true), 5 * 3, TimeUnit.SECONDS
);
scheduler.schedule(
() -> System.exit(0), (5 * 3) + 5, TimeUnit.SECONDS
);Die Zeitangaben sind relativ (\(x\) TimeUnits ab “jetzt”). Soll ein absoluter Zeitpunkt angegeben werden, muss der umgerechnet werden:
System.currentTimeMillis() liefert die Anzahl der Millisekunden seit dem 01.01.1970 00:00:00 (Beginn der “UNIX-Epoche”, eine gängige (POSIX-Standard) Zeitrepräsentation in vielen Betriebssystemen).
4.3.7 Heuristik zur Dimensionierung der Thread Pool Größe2
Die Größe eines Thread Pools ist in Abhängigkeit der gegebenen Hardware-Ressourcen (\(N_{CPU}\)), der anderen Aufgaben des Systems (\(U_{CPU}\)3) und der Verarbeitungscharakteristik (\(\frac{W}{C}\)) zu optimieren:
\[\begin{eqnarray} N_{CPU} &=& Anzahl~der~CPUs\\ &=& \mathtt{Runtime.getRuntime().availableProcessors()}\\ U_{CPU} &=& CPU~Auslastung~~~(0 < U_{CPU} \le 1)\\ \frac{W}{C} &=& Verh.~zwischen~Wartezeit~und~Rechenzeit\\ N_{Threads} &=& N_{CPU} \times U_{CPU} \times (1 + \frac{W}{C}) \end{eqnarray}\]
bei rechenintensiven Tasks (nie im BLOCKED-, WAITING- oder TIMED_WAITING-Zustand -> \(\frac{W}{C}=0\)) auf einem halb ausgelasteten System (\(U_{CPU}=\frac12\)):
\[\begin{eqnarray} N_{Threads} &=& N_{CPU} \times \frac12 \times (1 + 0) = N_{CPU}\\ &=& \mathtt{Runtime.getRuntime().availableProcessors()/2} \end{eqnarray}\]
Exkurs: Da es z.B. bei “page faults” im Memory Management des Betriebssystems (d.h. RAM eines Prozesses muss erst verschoben werden) in der Praxis selbst bei sehr rechenintensiven Aufgaben (\(\frac{W}{C}=0\)) gelegentlich zu Wartezyklen kommt, ist es ratsam, einen “überzähligen” Thread zu haben, so dass es währenddessen nicht zu Leerlauf auf einem der verfügbaren Cores kommt.4
Da die CPU-Auslastung schwer vorherzusagen ist, scheint es zudem ratsam, \(U_{CPU}=1\) anzunehmen.
Bei rechenintensiven Tasks (nie im BLOCKED-, WAITING- oder TIMED_WAITING-Zustand -> \(\frac{W}{C}=0\)) bei \(U_{CPU}=1\) ergibt sich also: \[\begin{eqnarray}
N_{Threads} &=& N_{CPU} + 1\\
&=& \mathtt{Runtime.getRuntime().availableProcessors() + 1}
\end{eqnarray}\]
4.3.8 Exceptions bei Thread Pool Verwendung
void execute(Runnable r)- In
r.run()auftretende unbehandlete Exceptions werden sofort geworfen. - Der betroffene Pool-Thread terminiert.
- In
Future<T> submit(Callable<T> c)\(\to\)f- In
c.call()auftretende unbehandelte Exceptions werden “aufgehoben” und erst vonf.get()geworfen. - Soll eine Ausnahme lokal in
c.call()behandelt werden (z.B. zum Aufräumen), kann sie danach imcatch-Block erneut geworfen werden (mitthrow), um sie auch dem Aufrufer vonf.get()weiterzuleiten.
- In
4.3.9 Exkurs: “CompletionService” für voneinander unabhängige Tasks5
Der ExecutorCompletionService<?> stellt einen komfortablen Dienst zum Einsammeln von Ergebnissen aus einem Thread Pool bereit, der eingesetzt werden kann, wenn diese Ergebnisse unabhängig voneinander sind.
var pool = Executors.newCachedThreadPool();
var tasks = new ArrayList<Callable<String>>();
tasks.add(() -> "calc c1");
tasks.add(() -> "calc c2");
tasks.add(() -> "calc c3");
var completionService = new ExecutorCompletionService<String>(pool);
for (var callableTask : tasks) {
completionService.submit(callableTask);
}
try {
for (var i = 0; i < tasks.size(); i++) {
var future = completionService.take();
System.out.printf("Result %2d: %s\n", i, future.get());
}
} catch (InterruptedException | ExecutionException e) {
// ...
}
pool.shutdown();take() liefert hierbei immer das nächste fertige Future<?>, egal in welcher Reihenfolge submit() ausgeführt wurde