11 Aktor-Modell und Umsetzung im Akka-Framework
11.1 Aktor-Modell
- Idee aus den 70er Jahren (Hewitt, Bishop und Steiger (1973))
- lange exotisch (u.a. Erlang)
- hauptsächlich in Kommunikationssyst.: Telefonvermittlung, Whatsapp, RabbitMQ
- inzwischen “Hot Topic” (u.a. Swift)
- im Prinzip nebenläufige Objekte
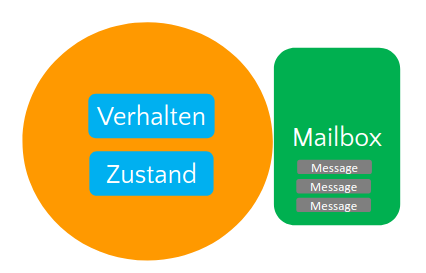
- eigener Zustand, eigenes Verhalten
- Kommunikation mit anderen Aktoren durch Senden von Nachrichten (Methodenaufruf)
- Nachrichtenzustellung durch Ablaufumgebung sichergestellt
11.1.1 Elemente des Aktor-Modells
- kein geteilter Zustand zwischen Aktoren
- keine Synchronisierung erforderlich
- jeder Aktor hat eigene Mailbox
- eingehende Nachrichten
- Nachrichten werden sequentiell bearbeitet
- Nachrichten werden asynchron zugestellt
- ein Aktor kann neue Aktoren erzeugen
- Verteilung von Teilaufgaben
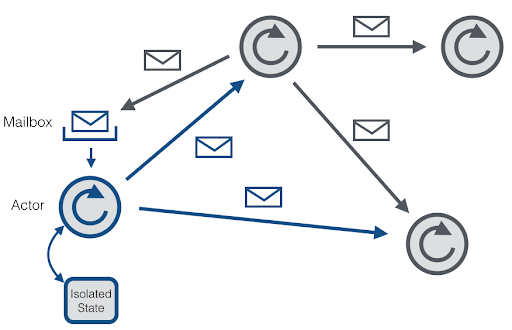
- Aktor kann Nachricht nehmen und verarbeiten (verbrauchen)
- oder unverändert weiterleiten
- Alternativ: Verarbeitung = neue Nachricht(en) erzeugen und weiterleiten
- Aktor kann Nachrichten an sich selber senden
11.1.2 Nachrichten
- Aktor interagieren durch Nachrichtenaustausch
- Nachrichten werden asynchron zugestellt
- empfangender Aktor blockiert nicht bis zum Empfang
- Mailbox \(\neq\) Channel
- mehrere Produzenten für eine Mailbox möglich
- ein Empfänger behandelt die Nachrichten mehrere anderer Aktoren, die in seiner Mailbox ankommen, synchron
- “put” und “take” sind atomare Operationen
- Nachrichten immutable
- Aktor kann Nachricht nehmen und verarbeiten (verbrauchen)
- oder unverändert weiterleiten
- Alternativ: Verarbeitung = neue Nachricht(en) erzeugen und weiterleiten
- Aktor kann Nachrichten an sich selber senden
11.1.3 Aktoren \(\neq\) Threads
- Die Anzahl der Aktoren kann größer sein, als die Zahl der sinnvoll zu behandelnden Threads (wie bei Fibers, Go-Coroutinen etc.)
- Es gibt eine Komponente im Aktor-System (“Dispatcher”), die eine Zuordnung von Aktor zu Thread (z.B. aus einem Threadpool) übernimmt.
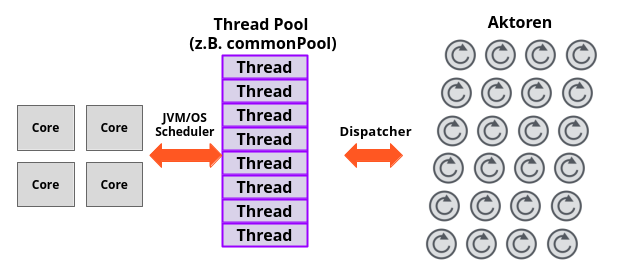
- Die Verarbeitung einer Nachricht aus der Mailbox eines Aktors wird vom Dispatcher ausgewählt und in einem Thread ausgeführt
- Der
commonPoolbei Java ist vom TypForkJoinPoolund hat eine feste Thread-Anzahl wie ein Fixed Thread Pool, unterstützt aber zusätzlich auch “Work-Stealing”.
11.2 Aktoren überwachen Aktoren
11.2.1 Aktor-Programme und Fehler
Aktoren überwachen andere Aktoren (solche “Überwacher” heißen supersivor).
Statt “defensive programming” oder Exception Handling: “let it crash”:
- Worker (Aktor, der konkrete Anwendungsaufgabe umsetzt) ist nur für Verarbeitung korrekter Eingabeparameter gemacht.
- Fehlerbehandlung wird in den Supervisor verschoben.
11.2.1.1 Vorteile
- Programme sind einfacher (Fehlerbehandlung ausgelagert).
- Da Aktoren getrennt sind und keine Variablen teilen, besteht keine Gefahr, dass mehr als ein Programmteil abstürzt (Worker stürzt ab, Supervisor bleibt).
- Supervisor kann weitergehende Fehlerbehandlungsstrategien auch für unvorhergesehene Situationen implementieren und zentrale Protokollierung vornehmen.
11.2.2 Hierarchie von Error Kernels
Aktoren (Supervisor) überwachen Aktoren (Worker oder Supervisor)
- sie werden über Abstürze informiert
- Ersatz für Exception Handling
- sehr robust
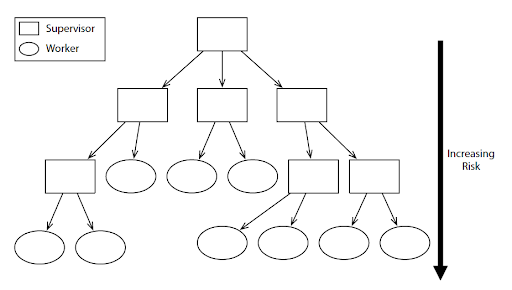
“Increasing Risk”: Aktor mit höherem Risiko sollen weiter unten in der Hierarchie angeordnet werden.
11.2.3 Error Kernel Design Pattern
- Der Teil eines Programms der absolut korrekt sein muss, da er andere (potenziell unsicherere) Teile überwacht und ggf. neu startet.
- Man sollte bestrebt sein, den Error Kernel zu minimieren, damit wenigstens dort Fehlerfreiheit garantiert werden kann.
- Im Aktor-Paradigma sollte jeder Prozess der einen Anwendungszweck hat (Worker) einen übergeordneten Supervisor-Prozess haben, der als dessen Error-Kernel fungiert.
- Es spricht nichts dagegen, auch komplexere Supervisor-Prozesse von einfacheren Error-Kernel-beinhaltenden Meta-Supervisor-Prozessen überwachen zu lassen.
Dieses Entwurfsmuster wurde zusammen mit der Programmiersprache Erlang (“Ericson Language”) und dem damit verbundenen Framework OTP entwickelt1. Es ist im Telekommunikationsumfeld weit verbreitet. Tipp: Moderne Sprachvariante: Elixir2
Mit diesem Ansatz werden ultra-robuste Systeme für den produktiven Betrieb kritischer Anwendungen entwickelt.
11.2.4 Design Prinzipien für Aktoren
- Ein Aktor sollte nur eine klar abgegrenzte Aufgabe haben (“single responsibility”-Prinzip)
- Spezifische Supervisor: Ein Supervisor sollte nur genau eine Art von Worker überwachen.
- Einfacher Error Kernel: Die Wurzel in der Überwachungshierarchie sollte so einfach wie möglich sein, um Fehler zu vermeiden, die nicht abgefangen werden können.
- Fehler-Zonen: Fehler sollten sich nur auf einen abgegrenzten Teil der Hierarchie von Supervisors/Workers auswirken.
11.3 Akka (Java API)
11.3.1 Auf Nachrichten reagieren
Dieser Aktor kann auf Nachrichten vom Typ Greeting reagieren, der hier als record implementiert ist. Falls eine solche Nachricht aus der Mailbox des Aktors gelesen wird, wird sie mit der Methode, die hier als Lambda-Ausdruck angegeben wurde, verarbeitet.
Solange die Aktoren lokal sind und nur innerhalb einer JVM-Instanz Nachrichten austauschen, können beliebige Objekte als Nachricht versendet werden. Nächste Woche werden verteilte Aktor eingeführt. Werden zwischen Aktoren, die auf mehreren Rechnern verteilt sind, Nachrichten ausgetauscht, bedeutet dies Netzwerkkommunikation. Dazu müssen Objekte serialisiert werden um sie zu versenden und der Empfänger muss solche Nachrichten deserialiseren, d.h. Objekte aus den Nachrichten erzeugen. In dem Fall müssen Nachrichten das Serializable-Interface implementieren.
public class NewActor extends AbstractActor {
@Override
public Receive createReceive() {
return receiveBuilder()
.match(Msg1.class, this::receiveMsg1)
.match(Msg2.class, this::receiveMsg2)
.match(Msg3.class, this::receiveMsg3)
.build();
}
private void receiveMsg1(Msg1 msg) {...}
private void receiveMsg2(Msg2 msg) {...}
private void receiveMsg3(Msg3 msg) {...}
}Dieser Aktor kann auf Nachrichten der Typen Msg1, Msg2 und Msg3 reagieren.
AbstractActor und AbstractLogging Actor unterscheiden sich dadurch, dass der AbstractLoggingActor einen Logger hat, auf den mit der Methode log aus der Aktor-Instanz zugegriffen werden kann.
Anstatt als Lambda-Ausdruck wie bei DemoMessagesActor werden hier die Aktionen als Funktionsreferenzen mit dem ::-Operator angegeben. Beides ist möglich.
11.3.2 Aktor programmatisch erzeugen
ActorRefist der Basis-Typ für Aktoren in AkkaactorOfist Factory-Methode zum Erzeugen neuer Aktoren- Aktoren werden immer in einem (“Eltern”-) Kontext erzeugt
Akka.system()ist “Wurzel”-Kontext- Auswahl des Aktor-Typs durch
Props.create(…): hier Implementierungsklasse des Aktors angeben – z. B.MyActor - optional kann als zweiter Parameter von
actorOfein Akka-interner Name angegeben werden, über den der Aktor identifiziert werden kann
Props.create(MyActor.class) ist eine von vielen Möglichkeiten einen MyActor zu instantiieren und im Akka-System “aktiv zu machen”. In diesem Fall würde der Default-Konstruktor von MyActor zur Instantiierung verwendet werden. In manchen Fällen soll aber ein anderer Konstruktor mit Parametern verwendet werden. Dafür und für die Benutzung von spezifischen Factory-Methoden gibt es andere Varianten für die Verwendung von Props, die hier aber nicht weiter betrachtet werden.
11.3.2.1 Kind-Aktor in Eltern-Aktor erzeugen
11.3.3 Aktor-Hierarchie

Der Kontext, in dem ein Aktor erzeugt wurde, bestimmt die Ebene in der Hierarchie, die zwischen den Aktoren herrscht. Es handelt sich aber trotz der Benennung von “Eltern”- und “Kind”-Ebene nicht um eine Vererbungshierarchie. Die Hierarchie zeigt sich in URL’s, mit denen Aktoren referenziert werden können.
getContext() würde hier in einer Methode in parent aufgerufen werden. Das Ergebnis wäre dann der Kontext des “myactor”-Aktors. Wenn in diesem Kontext ein weiterer Aktor “sub” mit actorOf erzeugt wird, ist dessen Kontext dem vorigen untergeordnet.
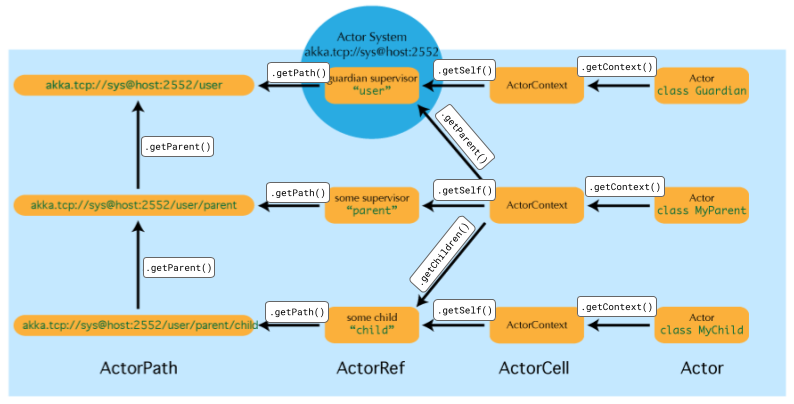
{kind=link}
In der obigen Abbildung sind drei Ebenen von Aktoren dargestellt. Mit getParent() kann man von einem ActorContext ausgehend die ActorRef des Eltern Aktors bekommen und mit getChildren eine Liste der ActorRef der Kinder.
Mit getPath() kann zu einer ActorRef die URL ermittelt werden (ActorPath).
Von seinem Kontext ausgehend kann ein Agent mit getSelf() seine eigene ActorRef ermitteln.
Bei Akka können die Aktoren in einem Netz über mehrere Rechner verteilt werden. Über die URL können wie in der obigen Abbildung dargestellt dann auch entfernte (“remote”) Aktoren referenziert werden. Das Schema der URL ist dann nicht akka, sondern akka.tcp. Außerdem wird dann in der URL der Host Name des Rechners angegeben, auf dem das Aktor-System läuft, (im Beispiel host) sowie die Portnummer (im Beispiel 2552) und der Name des Aktor-Systems selbst (im Beispiel sys).3
11.3.4 Nachrichtenversand
Man kann zwei unterschiedliche Dialogarten bzw. “Sprechakte” zwischen Aktoren unterscheiden: tell und ask.
11.3.4.1 “Fire-and-Forget”-Versand mit “tell”
“Fire-and-Forget” soll andeuten, dass bei diesem Sprechakt nur gesendet wird. Eine etwaige Antwort ist strukturell nicht direkt mit dem vorausgegangenem Senden verknüpft. Inhaltlich kann der Sprechakt “Frage-Antwort” (“Request-Reply”), aber durch zwei “tells” abgebildet werden. Wenn in dem Antwort-“tell” die Frage wiederholt wird, hat der Empfänger der Antwort auch keinen Bedarf die Antwort dem vorigen Frage-“tell” zuzuordnen.
targetist eineActorRef, an deren Aktor die Nachricht gesendet werden soll.- Die Nachricht selbst (hier im Beispiel der String “
Hello”) kann von einem beliebigen Typ sein. Sollte das Aktor-System auf mehrere Rechner verteilt sein, muss das Objekt, das als Nachricht versendet werden soll, serialisiert werden, um es über TCP zu versenden. Die Voraussetzung dafür ist, dass die Klasse des Objekts das InterfaceSerializableimplementiert. getSelf()-> Der Aktor, der dies aufruft. Ergebnis ist vom TypActorRef.getSender()-> Der Aktor, der die Nachricht gesendet hat, die gerade verarbeitet wird. Ergebnis ist vom TypActorRef.tell()-> Methode vonActorRef. Der Aktor, an dem diese Methode aufgerufen wird, bekommt eine Nachricht zugesandt (in die Mailbox geschrieben).- Die Nachricht ist der erste Parameter der Methode. Der Typ kann beliebig sein, sollte aber vom Empfänger verarbeitet werden. Sonst wird sie in der “Deadletter-Mailbox” gespeichert.
- Der zweite Parameter ist der Absender der Nachricht (vom Typ
ActorRef). - Das muss nicht der Aktor sein, der die Nachricht verschickt. Sondern derjenige, der die Antwort auf diese Nachricht erhalten soll (der beim Empfänger mit
getSender()ermittelt wird).
11.3.4.2 “Request-Reply”-Versand mit “ask”
Das Ergebnis des Versands von Nachrichten mit ask ist ein CompletableFuture. Wenn die erwartete Antwort später eintrifft, wird der Inhalt des darin enthaltenen Future realisiert.
import static akka.pattern.PatternsCS.ask;
CompletableFuture<Object> future1 = ask(actorA, "request 1", 1000);
CompletableFuture<Object> future2 = ask(actorB, "request 2", 1000);
CompletableFuture<Result> transformed =
CompletableFuture.allOf(future1, future2).thenApply(v -> {
String x = (String) future1.join();
String s = (String) future2.join();
return new Result(x, s);
});- Niemals ein CompletableFuture als Nachricht versenden: Wenn Aktoren auf unterschiedlichen Rechnern sind, müsste das Future zum Versand serialisiert werden, was nicht funktioniert.
11.3.5 Design-Prinzipien für Nachrichtenversand
- “Fire-and-Forget” statt “Request-Reply”: Nachrichten sollten tendenziell eher nicht auf Aufforderung versendet werden, sondern aufgrund eines Ereignisses/situativen Zustands.
- tell vor ask bevorzugen: mit tell kann genauso ein Request-Reply Kommunikationsmuster umgesetzt werden: In vielen Fällen ist es nicht erforderlich eine Korrelation zwischen Anfrage und Antwort herzustellen.
- besser: Frage in Antwort wiederholen (bzw. wesentliche Elemente daraus), dann kann der Empfänger sie unabhängig von seiner Anfrage interpretieren
- ermöglicht auch das Antworten ans andere Aktoren als den ursprünglichen Anfrager
11.3.6 Monitoring
Die folgende Klasse ist ein Beispiel für einen Aktor, der einen anderen Aktor als “Supervisor” überwacht.
In diesem Beispiel wird beim Erzeugen eines WatchActors ein Kind namens “listener” vom Typ ListenerActor erzeugt. Im Konstruktor wird dann der erzeugende WatchActor zum “Supervisor” dieses Kinds gemacht.
public class WatchActor extends AbstractActor {
ActorRef child = getContext().actorOf(
Props.create(ListenerActor.class), "listener");
ActorRef lastSender;
public WatchActor() {
getContext().watch(this.child);
}
@Override
public Receive createReceive() {
return receiveBuilder()
.match(PoisonPill.class, (msg) -> {
getContext().stop(this.child);
this.lastSender = getSender(); })
.match(Terminated.class, (msg) -> {
if (msg.getActor() == this.child) {
this.lastSender.tell("finished", null);
} })
.build();
}
}- “
listener” wird als Kind vonWatchActorerzeugt (actorOfim Kontext des Aktors mit der KlasseWatchActor) WatchActorwird durchwatch(this.child)Supervisor von “listener”- Supervisors werden durch
Terminated.classüber Ende von überwachten Aktoren informiert
Erhält der WatchActor eine Nachricht vom Typ PoisonPill, wird das Kind gestoppt. Da das Kind vom WatchActor überwacht wird, wird der WatchActor über das Ende des Kinds informiert, wenn es (in der Zukunft) eingetreten ist. Dies geschieht dadurch, dass die Akka-Infrastruktur eine Terminated-Nachricht erzeugt, in der die ActorRef auf das Kind als Property namens Actor enthalten ist.
Wird solch eine Terminated-Nachricht über das Kind “listener” vom WatchActor empfangen, teilt der WatchActor dies dem Sender der PoisonPill mit, indem der String “terminated” zurücksendet.
11.3.7 Router
11.3.7.1 Abgrenzung Router zu Aktor
- Router ähnlich zu Aktoren
- kein eigener Zustand und Verhalten
- Eingang für eine Reihe nachgeordneter Aktoren (“Routees”)
11.3.7.2 Routee
- in der Regel gleichartig (z. B. von derselben Klasse)
- verarbeiten prinzipiell dieselben Nachrichtentypen
- Router kennt seine Routees
11.3.7.3 Nachrichtenversand über Router
- Nachricht an Routee wird nicht direkt geschickt, sondern über Router (“route”)
- Router ändert Nachricht nicht, Absender bleibt ursprünglicher Sender
- Router entscheidet aufgrund Entscheidungslogik, an welchen Routee weitergeleitet wird
- Router dient als “Load-Balancer” für Routees
Der Zweck von Routern ist es, Nachrichten zwischen einer Gruppe von möglichen Aktoren (“Routees”) ähnlich einem Load-Balancer zu verteilen. Router ähneln insofern Aktoren, dass Sie Nachrichten empfangen und an andere Aktoren weiterleiten. Allerdings sind sie dabei effizienter, weil Sie nicht die Standardstrukturen bspw. von Mailboxes verwenden.
Router brauchen keinen anwendungsspezifischen eigenen Zustand oder Verhalten sondern dienen lediglich als wiederverwendbarer Baustein zum Eingang für eine Reihe nachgeordneter Aktoren.
Die nachgeordneten Aktoren (“Routees”) sind in der Regel gleichartig (z. B. von derselben Klasse) und verarbeiten prinzipiell dieselben Nachrichtentypen.
Der Router ändert die Nachricht nicht, der Absender bleibt der ursprüngliche Sender. Wenn ein Routee eine Nachricht versendet, sollte der Router als Absender gesetzt werden.
11.3.7.4 Eingebaute Router-Typen
Der Router entscheidet aufgrund einer eigenen Entscheidungslogik, an welchen Routee die Nachricht weitergeleitet werden soll. Die folgenden Entscheidungslogiken für Router sind in Akka verfügbar:
11.3.8 Round-Robin Routing (RoundRobinRoutingLogic)
Nachrichten werden “reihum” an die zur Verfügung stehenden Routees gesendet. Man kann dabei nicht beeinflussen, welcher Routee der erste in der Reihenfolge ist.
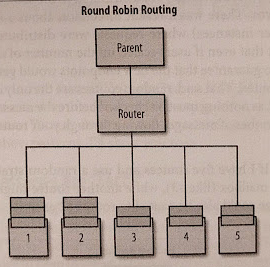
Dieser Router ist besonders geeignet, wenn die zu verteilenden Aufgaben, die hinter den weitergeleiteten Nachrichten stehen, mit einem ähnlichen Aufwand gelöst werden und wenn die Routees vergleichbare oder gemeinsam geteilte Ressourcen zur Verfügung haben. Falls die Aufgaben oder die Ressourcen jedoch ungleichmäßig sind, entsteht eine «Unwucht» bei der Verarbeitung.
11.3.9 Random Routing (RandomRoutingLogic)
Nachrichten werden an einen zufällig ausgewählten Routee gesendet.
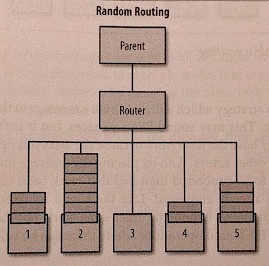
11.3.10 Smallest Mailbox Routing (SmallestMailboxRoutingLogic)
Nachrichten werden zufällig an einen der Routees mit der geringsten Anzahl von wartenden (unverarbeiteten) Nachrichten in der Mailbox gesendet. Allerdings kann solch ein Router nicht auf die Mailbox-Größe entfernter Routees zugreifen. Deshalb haben entfernte Aktoren bei dieser Routing-Logik immer die geringste Priorität.
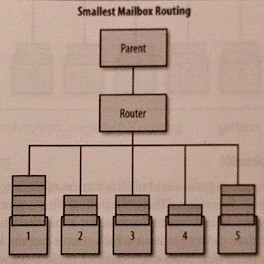
Selbst wenn eingehende Nachrichten immer an die kleinste Mailbox gesendet werden, gibt es keine Gewähr dafür, ob die Aufgaben hinter den Nachrichten einer volleren Mailbox nicht in Summe schneller abgearbeitet sind.
11.3.11 Broadcast Routing (BroadcastRoutingLogic)
Nachrichten werden vervielfältigt und jeder Routee erhält ein Exemplar der zu routenden Nachricht.
11.3.12 Scatter Gather First Completed Routing (ScatterGatherFirstCompletedRoutingLogic)
Wie bei der BroadcastRouterLogic werden Nachrichten an alle Routees weitergeleitet. Hier wird aber speziell das “ask”-Kommunikationsmuster unterstützt: Die zurückgegebene Antwort ist die des ersten der Routees, der eine Antwort zurückgibt. Der Anwendungszweck ist bei zeitkritischen Aufgaben, wenn mehrere Aktoren parallel dasselbe Problem zu lösen versuchen. Das am schnellsten erzeugt Ergebnis wird benutzt, die anderen werden ignoriert.
Die folgenden Gründe können dazu führen, dass die Routees unterschiedlich lange für die Bearbeitung derselben Aufgabe brauchen:
- Jeder Routee verwendet einen anderen Lösungsweg oder Algorithmus.
- Eine Zufallskomponente ist bei der Lösung beteiligt.
- Verteilte Ressourcen mit unterschiedlicher Auslastung oder Leistungsfähigkeit werden zur Lösung (also zur Ausführung der Routees) benutzt.
11.3.13 Router-Verwendung
Das folgende Listing zeigt exemplarisch, wie ein Router mit RoundRobinRoutingLogic-Verhalten Nachrichten zwischen fünf Routees vom Typ Worker aufteilt: Statt Nachrichten mit tell oder ask zu senden, werden sie mit route über den Router router verteilt:
var routees = new ArrayList<Routee>();
for (var i = 0; i < 5; i++) {
var routee = getContext().actorOf(Props.create(Worker.class));
getContext().watch(routee);
routees.add(new ActorRefRoutee(routee));
}
var router = new Router(new RoundRobinRoutingLogic(), routees);
// ...
router.route(message, getSelf());11.3.14 Kopplung von Router und Routees
11.3.14.1 Gruppe
Im Fall einer Router-Group sind Router und Routees weniger eng gekoppelt:
- Der Router erzeugt “seine” Routees-Aktoren nicht selber, sondern bekommt sie mitgeteilt.
- Er überwacht die Routees nicht selber.
11.3.14.2 Pool
Im Fall eines Router-Pools sind Router und Routees enger gekoppelt als bei einer Gruppe:
- Der Router erzeugt “seine” Routees-Aktoren selber und überwacht sie.
- Sollte ein Routee terminieren, entfernt der Router sie aus seiner Routee-Liste.
11.3.14.3 BalancingPool
Beim BalancingPool teilen alle Routees eine Mailbox.
Die Arbeit (Nachrichten in der Mailbox) werden also optimal auf die zur Verfügung stehenden (Worker-) Ressourcen aufgeteilt: Kein Routee muss auf Nachrichten warten während andere Routees mit der Abarbeitung der Nachrichten nicht hinterherkommen.
11.3.15 Exkurse4
11.3.15.1 Konfigurationsdateien
Neben der programmatischen Verwendung von Routern kann auch der konfigurative Ansatz verwendet werden.
Das config-Framework ist ein moderner Ersatz von Properties-Dateien, ist aber nicht Teil des Java-Standard API’s, sondern muss als Library eingebunden werden. Es wird von Akka intensiv genutzt. config ist daher Teil der Abhängigkeiten (“dependencies”) von Akka.
Sucht die Konfigurationsdatei config.conf im current working directory (das Verzeichnis, von dem aus die Anwendung gestartet wird (nicht unbedingt das Verzeichnis, in dem die Klasse liegt).
Bei Verwendung von Maven: src/main/resources/config.conf
11.3.15.2 Router-Gruppe über Konfiguration erzeugen
public class Main {
public static void main(String... args) {
var sys = ActorSystem.create("sys", ConfigFactory.load("config"));
sys.actorOf(Props.create(WorkerActor.class), "worker1");
sys.actorOf(Props.create(WorkerActor.class), "worker2");
sys.actorOf(Props.create(WorkerActor.class), "worker3");
var r = sys.actorOf(FromConfig.getInstance().props(), "router");
}
}11.3.15.3 Verteilte Akka-Systeme
Die obige Konfiguration zusammen mit MainClassOfApp (s.o.) würde auf dem Rechner 10.136.117.1 ein Akka-System mit der URL akka.tcp://main@10.136.117.1:4711 starten.
Die obige Konfiguration zusammen mit MainClassOfApp (s.o.) würde auf dem Rechner 10.136.117.2 ein Akka-System mit der URL akka.tcp://main@10.136.117.2:8080 starten.
Um einen entfernten Aktor von 10.136.117.1 aus auf 10.136.117.2 zu finden, müsste man auf Rechner 10.136.117.1 folgendes ausführen:
Die Nachricht “Hallo von 10.136.117.1” wird dann an den Aktor /user/worker auf dem Rechner 10.136.117.2 geschickt.
Um einen entfernten Aktor von 10.136.117.1 aus auf 10.136.117.2 zu erzeugen, müsste man auf Rechner 10.136.117.1 folgendes ausführen:
Aktor /user/worker wird dann auf dem Rechner 10.136.117.2 erzeugt und die Nachricht “Hallo von 10.136.117.1” wird an ihn geschickt.
11.3.15.4 Entfernte Aktoren über Konfiguration
Bei folgender Konfiguration (Ausschnitt) auf 10.136.117.1 würde ein lokaler Zugriff auf den Aktor namens remote/... (Name beginnt mit remote/) effektiv an den entsprechenden Aktor auf dem Akka-Knoten auf 10.136.117.2 erfolgen:
Das Wildcard-Symbol * funktioniert nur innerhalb von Anführungsstrichen. Ein partielles Matching wie z. B. worker-* funktioniert leider nicht. Es kann vielmehr immer nur ein Aktor-Name (was zwischen “/” steht) ersetzt werden.
11.3.15.5 Entfernte Aktoren und Nachrichten
Nachrichten-Objekte müssen von einer serialisierbaren Klasse instanziiert werden, damit sie als Byte-Abfolge über eine Netzwerkverbindung versendet werden können:
Die serialVersionUID ist eine eindeutige Zahl, mit der die Klasse beim Empfänger wiedererkannt werden kann (hilft bei Doppelbenennungen und Versionskonflikten).
11.3.15.6 Router-Gruppe
Das folgende Listing zeigt einen Teil der Konfiguration für einen Router.
Aus solch einer Konfiguration kann der Router zusammen mit seinen Routees programmatisch erzeugt werden:
über den dann wieder Nachrichten wie im obigen Code-Beispiel versendet werden können:
11.3.15.7 Router für verteilte Routees
Der konfigurative Ansatz ermöglicht zudem analog zur Definition eines Routers mit lokalen Routees die effektive Nutzung verteilter Ressourcen. Im folgenden Listing ist die Konfiguration eines RoundRobinRoutingLogic-Routers und einer verteilten Gruppe von drei Routees vom Typ Worker auf den Hosts host1, host2 und host3 dargestellt.
bei jeweils einem Routee auf jedem der drei Knoten host1, host2 und host3:
Als Pool von zehn gleichmäßig auf host2 und host3 verteilten Routees:
{kind=link}