10 Communicating Sequential Processes (Entwurfsmuster mit Kanälen und Rendezvous)
10.1 Rendezvous-Punkte mit der Exchanger-Klasse
10.1.1 Exchanger: Synchroner Austausch
- synchroner, typisierter Austauschkanal zwischen zwei Teilnehmern
- zeitgleicher Austausch von Objekten zwischen zwei Threads
- erster am Rendezvous-Punkt (hier
t1) wird angehalten, bis Partner geliefert hat

10.2 Koordinierter Datenaustausch über BlockingQueue
10.2.1 Queue-Interfaces

Deque⇒ “Double Ended Queue” (Queue, bei der von beiden Seiten zugegriffen werden kann)BlockingQueue: blockiert Nutzer, solange sie voll ist (beim Einfügen) bzw. solange sie leer ist (beim Entnehmen)TransferQueue: Producer blockiert, bis Consumer konsumiert
10.2.2 Queue-Interfaces ohne transitiv vorhandene Relationen
Dasselbe wie im vorigen Diagramm, nur ohne redundante Relationen, die aus der Transitivitätseigenschaft der Vererbungsrelation hergeleitet werden können:

10.2.3 Methoden von BlockingQueue<E>
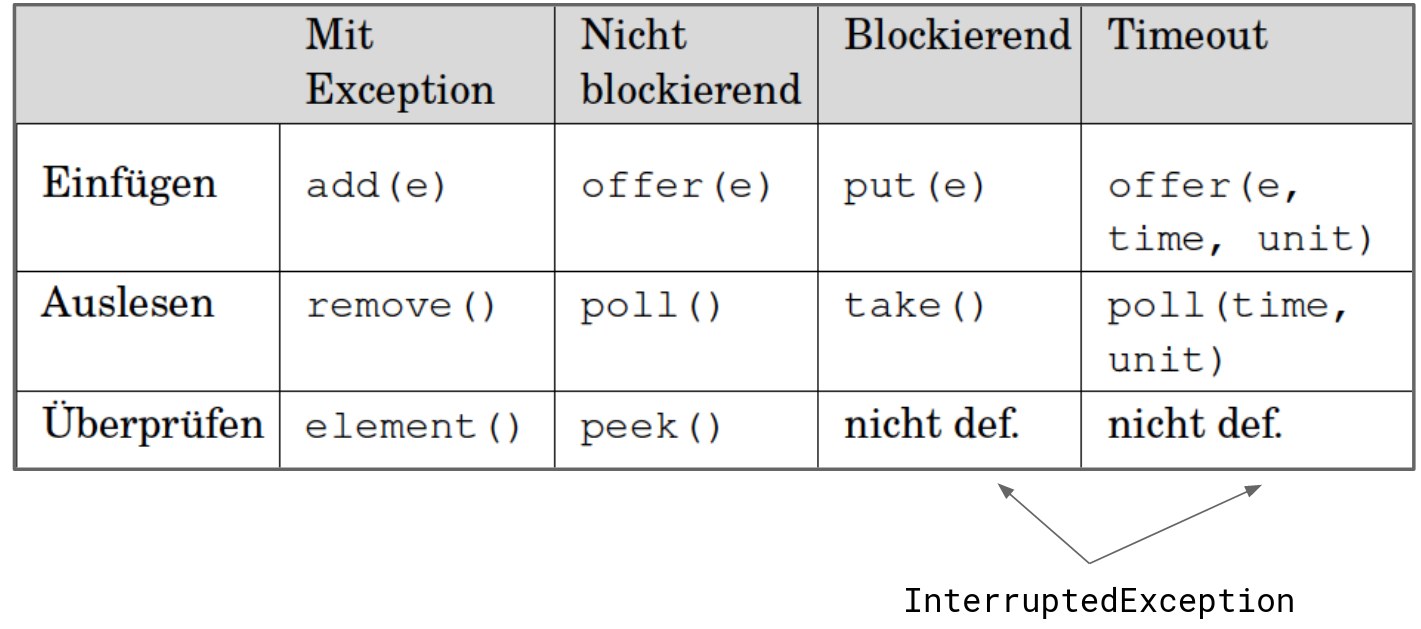
boolean offer(E e): Fügt ein Element am Ende der Queue ein. Die Rückgabe gibt an, ob die Operation erfolgreich war. Die Rückgabe ist insbesondere bei platzbeschränkten Queues wichtig. Durchfalsewird signalisiert, dass das Element nicht aufgenommen werden konnte.boolean offer(E e, long timeout, TimeUnit unit): Die Wirkung ist wie beioffer(E e)mit dem Unterschied, dass die maximale Wartezeit durch die beiden letzten Parameter spezifiziert wird.E poll(): Entnimmt ein Element vom Anfang der Queue. Liefertnull, falls kein Element vorhanden ist.E poll(long timeout, TimeUnit unit): Die Wirkung ist wie beipoll(), wobei hier die maximale Wartezeit angegeben wird.void put(E e): Fügtein die Queue ein und wartet ggf., bis ein entsprechender Platz in der Queue vorhanden ist.- **
E take(): Entnimmt ein Element vom Anfang der Queue und wartet (blockiert) ggf., bis ein Element vorhanden ist.
10.2.4 Implementierungen
ArrayBlockingQueue<E>ist eineQueuemit einer festen Größe (Kapazität).LinkedBlockingQueue<E>existiert sowohl als kapazitätsbeschränkte als auch als unbeschränkteQueue.DelayQueue<E>kann nur Objekte aufnehmen, deren Klasse das InterfaceDelayedimplementiert.PriorityBlockingQueue<E>sortiert mithilfe dercompareTo-Methode bzw. mit dem explizit angegebenenComparator-Objekt ihre verwalteten Elemente.SynchronousQueue<E>ist eine blockierendeQueue, bei der die beiden beteiligten Threads aufeinander warten müssen. Zu bemerken ist, dass eineSynchronousQueuekeine Kapazität hat. Die Kommunikation der beiden Partner muss wie beiExchangesynchron stattfinden. Einige Methoden desBlockingQueue-Interface (wiepoll,peeketc.) haben keine Bedeutung (sie liefern zum Beispiel immernullzurück).

10.2.5 Implementierungen ohne transitiv vorhandene Relationen
Dasselbe wie im vorigen Diagramm, nur ohne redundante Relationen, die aus der Transitivitätseigenschaft der Vererbungsrelation hergeleitet werden können:

10.2.6 Entkopplung bei Erzeuger/Verbraucher
- komplette Entkopplung bei asynchronen Methoden (
offer()/poll()) - Synchronisierung von Erzeuger/Verbraucher mit blockierenden Methoden (
put()/take())

10.2.7 mehrere Erzeuger/Verbraucher
- im Gegensatz zum Exchanger können beliebig viele Erzeuger und Verbraucher auf die Queue zugreifen
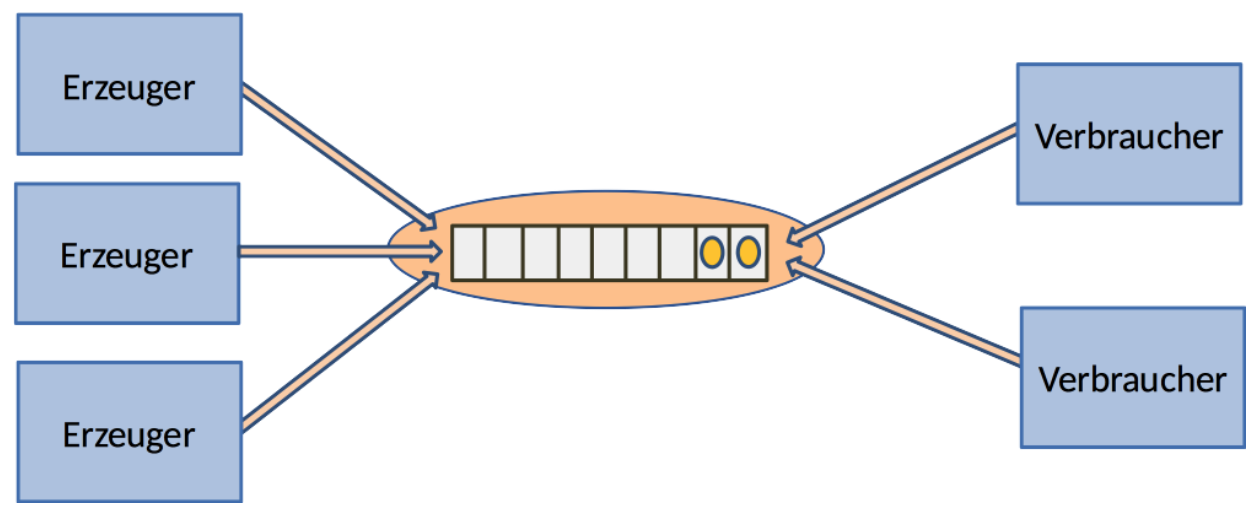
10.2.8 Benutzungsmuster: Filterverkettung
Hier geht es um die Bearbeitung von Aufgaben, die sich aus Elementen, z.B. einer Abfolge von Teilaufgaben zusammensetzen. Außerdem werden diese Teilaufgaben in einer Kette von Verarbeitungsschritten verarbeitet. Die Verarbeitungsschritte (“Levels”) werden oft “Filter” genannt (daher “Filterverkettung”), da die fortgesetzte Filterung von Daten eine häufige Anwendung ist. Auf jeder Verarbeitungsstufe können aber neben Filtern auch Transformationen (Anwendung einer Funktion: “Mapping”) oder Aggregationen (“Reduce”) erfolgen.
- verbreitetes Muster auf der Basis Erzeuger/Verbraucher
- auf jedem Level können Filter, Map” oder Reduce ablaufen

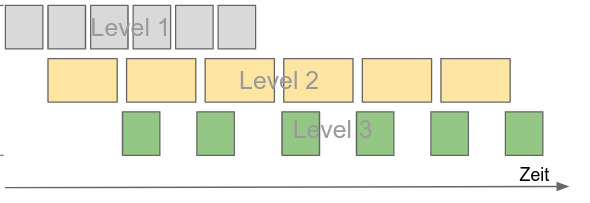
In diesem Beispiel passiert folgendes:
- Level 1 schreibt einen Output Element für Element n die linke Queue
- Level 2 liest Elemente aus der Queue als Input und schreibt seinen Output in die rechte Queue
- Level 3 liest diese Elemente aus der rechte Queue als seinen Input
sequentielle Verarbeitung:

Die Farbe der Vierecke soll zeigen auf welchem Level die Aufgabe verarbeitet wird.
Im Fall der sequentiellen Verarbeitung werden erst alle Aufgaben auf Level 1 verarbeitet, dann alle auf Level 2, dann auf Level 3.
Die Länge der Vierecke soll die Verarbeitungsdauer repräsentieren.
Die Verarbeitung jeder einzelnen Teilaufgabe (Element aus linker Queue) auf Level 2 (gelb) dauert im hier gezeigten Beispiel also länger als auf den anderen beiden Leveln (z.B. weil der dort implementierte Algorithmus einen höheren Aufwand hat).
1 Core benötigt
10.2.9 Benutzungsmuster: Filterverkettung
10.2.9.1 Parallelisierung
- alle Verarbeitungsstufen arbeiten parallel
Wenn die Verarbeitungsstufen Level 1-3 hingegen parallel arbeiten, ergibt sich eine kürzere Gesamtdurchlaufzeit:
Parallelisierung:
Das Beispiel ist so gewählt, dass sich aufgrund der längeren Verarbeitungszeit pro Aufgabe auf Level 2 ergibt, dass auf Level 3 Pausen entstehen, in denen auf dieser Verarbeitungsstufe gewartet werden muss, bis der nächste Input von Level 2 zur Verfügung steht.
- 3 Cores benötigt
10.2.10 Benutzungsmuster: Filterverkettung
10.2.10.1 Vertikale Skalierung
- vertikale Skalierung: Level 2 erhält zusätzliche Instanzen
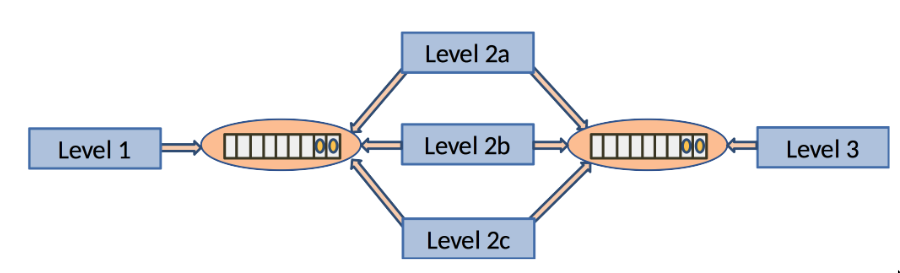
Da die langsame Verarbeitung auf Level 2 einen Flaschenhals darstellt und bewirkt, dass auf Level 3 unnötigerweise gewartet werden muss, werden mehr Instanzen von Level 2 gestartet.
Da die Verarbeitungsstufen durch die Queues weitgehend entkoppelt sind, ist das problemlos möglich. Ist jedoch die Reihenfolge der Elemente entscheidend, muss man bei dieser Art der Erhöhung des Durchsatzes durch weitere Parallelisierung dafür sorgen, dass die Reihenfolge später rekonstruiert werden kann, z.B. durch Nummerierung der Elemente mit nachträglicher Sortierung.
Skalierung:
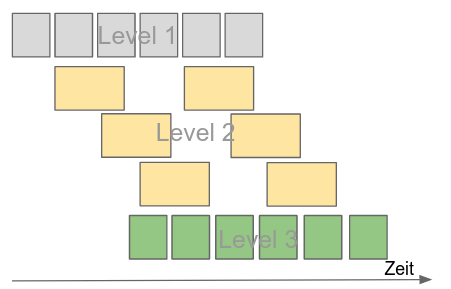
Im Beispiel ergibt sich, dass Level 3 nun nicht mehr warten muss, sondern durch die überlappende Verarbeitung der drei Level 2-Instanzen schritthaltend Elemente in die rechte Queue geschrieben bekommt.
- 5 Cores benötigt
10.2.11 Benutzungsmuster: Filterverkettung
10.2.11.1 Optimierung
- im Beispiel reichen zwei Instanzen für Level 2
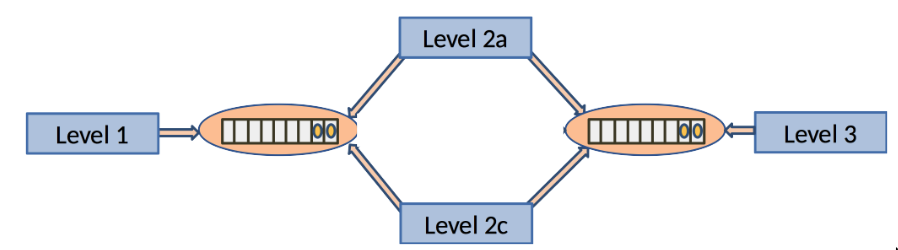
Level 3 ist nun zwar voll ausgelastet und braucht nicht mehr zu warten, das Beispiel ist aber so gewählt, dass nun die drei Instanzen von Level 2 Wartezeiten haben.
Optimierung:
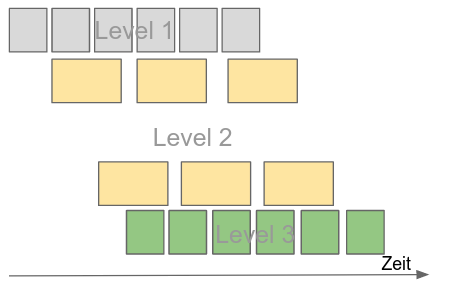
Hier ist es so, dass zwei Instanzen von Level 2 bereits ausreichen, damit Level 3 schritthaltend mit Elementen versorgt werden kann und keine Wartezeiten mehr hat.
Auf Level 2 gibt es nun zwar kurze Wartezeiten. Sie lassen sich aber nicht vermeiden, wenn insgesamt eine schnellstmögliche Verarbeitung erfolgen soll.
- 4 Cores benötigt
10.3 Kanäle in Go1
In diesem Abschnitt geht es darum, wie das Paradigma Communicating Sequential Processes (CSP, vgl. Hoare (1978)) in der Programmiersprache Go umgesetzt ist.
In der Programmiersprache Occam (vgl. Hyde (1995)) aus den 80er Jahren wurde dieses Konzept zuerst umgesetzt, hat aber noch keine große Verbreitung gefunden. Mit der Veröffentlichung der jetzt weit verbreiteten Programmiersprache Go hat sich dies jedoch geändert: In Go ist das Konzept CSP zentraler Bestandteil.
Bei CSP wird auf geteilten Speicher verzichtet. Stattdessen werden Daten immer explizit zwischen den nebenläufigen Programmteilen transferiert (“Do not communicate by sharing memory; instead, share memory by communicating” (Effective Go Website)). In der technischen Umsetzung wird bei diesem Ansatz (wie auch beim in diesem Aspekt vergleichbaren Actors-Modell, das seit Neuestem auch von der Programmiersprache Swift unterstützt wird) viel Optimierung betrieben, damit Speicherbereiche nicht kopiert werden müssen. Nichtsdestotrotz ist der Zugriff auf geteilten Speicher - wenn auch anfällig für Programmierfehler (“Race Conditions”) effizienter als CSP.
In Go gibt es neben dem hier dargestellten Ansatz CSP, der mit bei Go mit Co-Routinen arbeitet, jedoch auch die Möglichkeit, direkt Threads zu erzeugen und koordiniert mit Mutexen und Semaphoren auf geteilten Speicher zuzugreifen.
Wie die Umsetzung von CSP konkret in Go erfolgt, ist nicht prüfungsrelevant!
10.3.1 Communicating Sequential Processes
Das Modell Communicating Sequential Processes (CSP) für parallele Programmierung (Hoare (1978)) beinhaltet die folgenden Elemente:
- Kanal
- atomare Operationen zum Senden und zum Empfangen
- Channel-Deklaration: Typbindung
- Empfang von Nachrichten
- blockiert solange keine Nachricht im Kanal verfügbar ist
- Senden von Nachrichten
- synchroner Botschaftenaustausch (“Rendezvous”)
- Kanal puffert Nachrichten nicht, Sender wird solange blockiert, bis Nachricht abgeholt wurde
- asynchroner Botschaftenaustausch
- Kanal hat Queue mit endlicher Kapazität > 0
- wenn Kapazität noch nicht erreicht ist, wird der Sender nicht blockiert
- wenn die Kapazität erreicht ist, wird der Sender blockiert, bis die Queue wieder Platz hat und die Nachricht dort eingereiht wurde
- synchroner Botschaftenaustausch (“Rendezvous”)
10.3.2 Essentielle Go-Syntax: Kanäle und Co-Routinen
c <- a
Senden von Inhalt von Variablea(oder anderem Ausdruck) als Nachricht über Kanalca <- c
Nachricht von Kanalcempfangen und Variableazuweisen (man kann auch(<- c)als Ausdruck verwenden)go fun(...)
asynchroner Funktionsaufruf vonfun(...)- blockiert nicht, läuft als Co-Routine (“Go-Routine”) ab
- selektives Warten auf mehrere Channels, normalerweise in
for-Schleifedefault: falls keine Nachricht an den anderen Kanälen anliegt
10.3.3 Beispiel-Programm in Go
- 1
-
Deklaration des Kanals
quitfür Elemente vom Typbool - 2
-
Initialisierung des Kanals
quitfür Elemente vom Typboolmitmake - 3
-
hier synchrone Kommunikation (Kapazität
kapades Kanals ist hier 0)
Der Ablauf in dem Programm ergibt sich folgendermaßen:
- Nachdem der Kanal
quitals globale Variable initialisiert wurde, wird zuerst ProgrammteilAausgeführt. - Dann wird die Funktion
fasynchron als Co-Routine gestartet. Darin wird ProgrammteilBausgeführt.- Am Ende der Funktion
fwirdtruein den Kanalquitgeschrieben.
- Am Ende der Funktion
- Nebenläufig zu
Bwird ProgrammteilCausgeführt.- Nach
Cwird synchron aus Kanalquitgelesen. Dies blockiert so lange, bis etwas daraus gelesen werden kann - hier also, bistrueinquitam Ende vonfgesendet wurde.
- Nach
- Danach sind sowohl
Bals auchCfertig. Nun wird ProgrammteilDausgeführt. - Das Programm endet danach.
Man könnte das auch in Anlehnung an die Notation von Hoare (1978) folgendermaßen ausdrücken:
- Ausführungsreihenfolge:
A; (B | C); D
Das synchrone Senden/Empfangen über den Kanal quit funktioniert hier also als Rendezvous-Punkt zur Koordination der nebenläufigen Programmteile (main-Thread und f-Co-Routine).
In Java würde f in einem Thread-Objekt als run-Methode gestartet werden und man würde am Rendezvous-Punkt mit join auf das Ende dieses Threads warten (das ist dann aber kein vollständiges Rendezvous, da der Thread endet, bevor dieser Koordinationspunkt erreicht ist):
10.4 Logging
Logger nehmen Nachrichten an, die während des (operativen) Betriebs von Systemen ausgegeben oder gespeichert werden sollen. Dies kann für die Fehlersuche hilfreich sein oder aber auch zur Erfüllung von Audit-Anforderungen erforderlich sein.
10.4.1 Aufgaben beim Logging
- Ausgabe/Speichern von Nachrichten während des (operativen) Betriebs von Systemen.
- Nebenaufgabe: Soll möglichst wenig belasten
- RFC2 5424 (Gerhards (2009)): Severity-Levels (Emergency – Alert – Critical – Error – Warning – Notice – Informational – Debug)
- In verteilten Systemen: Herausforderung Timing (Uhren auf Knoten können unterschiedlich gehen), Herstellen von Bezügen zwischen Meldungen unterschiedlicher Knoten
- Zentrale Komponente; mehrere Puffer, damit loggende Threads sich nicht wegen der nebenläufigen Nutzung des Pufferspeichers gegenseitig blockieren
Das Logging ist eine Nebenaufgabe und sollte das System möglichst wenig belasten.
Generell unterscheidet man bei Loggern mehrere Schwerestufen: Eine Nachricht ist dabei immer einer Schwerestufe zugeordnet. Die Konfiguration des Loggers bestimmt, ab welcher Schwerestufe Nachrichten relevant sind und ausgegeben oder gespeichert werden sollen. Für den operativen Betrieb von Systemen können Nachrichten eines besonders hohen Schweregrads auch über Kommunikationssysteme an Verantwortliche geschickt werden, statt sie beispielsweise nur auf der Konsole auszugeben.
RFC 5424 ist ein Standard, der die Schnittstelle für einen zentralen Logging-Dienst in einem verteilten System beschreibt. Im RFC 5424-Standard sind die folgenden Schweregradstufen (“Severity-Levels”) definiert:
- Emergency
- Alert
- Critical
- Error
- Warning
- Notice
- Informational
- Debug
Das Logging in verteilten Systemen ist eine komplexe Aufgabe: Zu den Herausforderungen zählen der Umgang mit dem Timing (Uhren auf Knoten können unterschiedlich gehen) und das Herstellen von Bezügen zwischen Meldungen unterschiedlicher Knoten.
Ein zentraler Bestandteil von Loggern in verteilten Systemen sind mehrere Puffer, damit loggende Threads sich nicht wegen der nebenläufigen Nutzung des Pufferspeichers gegenseitig blockieren.