9 Coroutinen, Fibers
9.1 Theorie: Coroutinen und Fibers im Allgemeinen
9.1.1 Unterprogramme: Subroutinen, Coroutinen/Fibers, Threads

- Unterprogramme gibt es in unterschiedlicher Form
- Subroutinen: geschachtelt aufrufbar
- Threads (
run-Methode): stehen für sich
- Fibers sind beidem ähnlich:
- zu Subroutinen: im Aufrufer-Thread ausgeführt
- zu Threads: nebenläufige Programmteile
9.1.2 Subroutine
- geschachtelte Aufrufe von Subroutinen (andere Namen: “Methoden-”, “Funktionsaufruf”)
- Aufruf: Parameterwerte und lokale Variablen werden oben auf dem Stack abgelegt
- Ende einer Subroutine: Parameterwerte und lokale Variablen der Subroutine vom Stack entfernen, Rückgabewert auf Stack ablegen (optional)
- damit steht auf jeder Ebene der Aufrufhierarchie jeweils der richtige Ausführungskontext (Parameterwerte, lokale Variablen, Rückgabewert des letzten Subroutinenaufrufs) oben auf dem Stack zur Verfügung
9.1.2.1 Schrittweise Entwicklung des Call Stacks
Im Folgenden wird das folgende Programm benutzt:
9.1.2.1.1 Ausgangssituation
Vor dem Aufruf ist der Call Stack wahrscheinlich nicht leer, wir zeigen aber nur die obersten 13 Plätze (im Moment noch leer).

Call Stack ist vor dem Aufruf leer
9.1.2.1.2 Aufruf
Beim Aufruf von fac(4,1) wird zuerst Platz für den Rückgabewert (return) auf dem Stack geschaffen (hier aber nur aus didaktischen Gründen bereits allokiert – eigentlich reicht es, den Rückgabewert erst auf den Stack zu packen, nachdem die Aufurfparameter bereits entfernt sind) und darüber die beiden Aufrufparameter n und acc.

fac(4,1): die beiden Parameter + Platz für den Rückgabewert
9.1.2.1.3 Rekursionsschritt
Da der Rekursionsanker noch nicht erreicht ist, erfolgt der nächste Rekursionsschritt: fac(4-1, 1*4)

Rekursionsschritt: fac(4-1, 1*4)
9.1.2.1.4 Rekursionsschritt
Da der Rekursionsanker noch nicht erreicht ist, erfolgt der nächste Rekursionsschritt: fac(3-1, 4*3)

Rekursionsschritt: fac(3-1, 4*3)
9.1.2.1.5 Rekursionsschritt
Da der Rekursionsanker noch nicht erreicht ist, erfolgt der nächste Rekursionsschritt: fac(2-1, 12*2)

Rekursionsschritt: fac(2-1, 12*2)
9.1.2.1.6 Rekursionsanker
Da der Rekursionsanker erreicht ist, erfolgt die Rückgabe des Werts von acc. Zuerst werden die beiden Aufrufparameter des aktuellen Subroutinenaufrufs vom Stack entfernt. Dann wird der Rückgabewert auf den Stack geschrieben (in den markierten aus didaktischen Gründen bereits vorgesehenen Platz).

Rekursionsanker: Rückgabe von acc
9.1.2.1.7 Rückgabe
Auf der vorigen Aufrufebene wurde nur auf das Ergebnis des Rekursionsschritts gewartet, das nun direkt zurückgegeben wird, nachdem die Aufrufparameter vom Call Stack entfernt wurden.

Rückgabe der Rückgabe von acc
9.1.2.1.8 Rückgabe
Auf der vorigen Aufrufebene wurde nur auf das Ergebnis des Rekursionsschritts gewartet, das nun direkt zurückgegeben wird, nachdem die Aufrufparameter vom Call Stack entfernt wurden.

Rückgabe der Rückgabe der Rückgabe von acc
9.1.2.1.9 Rückgabe
Auf der vorigen Aufrufebene wurde nur auf das Ergebnis des Rekursionsschritts gewartet, das nun direkt zurückgegeben wird, nachdem die Aufrufparameter vom Call Stack entfernt wurden. Das finale Ergebnis von fac(4,1) liegt nun oben auf dem Call Stack. Der Aufrufer (System.out.println) kann nun darauf zugreifen.

Rückgabe der Rückgabe der Rückgabe der Rückgabe von acc
9.1.2.2 Exkurs: Eliminierung von Endrekursion1
Bei Endrekursion (“tail recursion”) wäre es wünschenswert, wenn der Rückgabewert am Ende nicht oben auf den Stack gepackt wird, sondern stattdessen der “vorige” Rückgabewert (oben auf dem Stack) geändert wird. Sonst ist die Aufruftiefe (= Anzahl der rekursiven Schritte) durch den Speicherplatz für den Stack begrenzt. Bei Endrekursion wird nämlich nur der allerletzte Rückgabewert des Rekursionsankers benötigt. Dieser Wert wird unnötigerweise am Ende Schritt für Schritt den Call-Stack “hinunterpropagiert”. Der jeweils vorher geltende Kontext (Aufrufparameter und lokale Variablen) wird aber später gar nicht mehr benötigt. Es wäre deshalb ratsam, wenn die jeweils neuen Aufrufparameter die vorigen auf dem Stack überschreiben würden.
Prinzipiell können Compiler die Situation “Endrekursion” automatisch erkennen und im Objektcode eine entsprechende Optimierung vornehmen (“tail call optimization” oder “tail call elimination”). Für Java ist dies jedoch aufgrund des internen Umgangs mit dem Stack u.a. für die Durchsetzung des Sicherheitsmodells nicht so definiert.
9.1.2.2.1 Beispiel Clojure
Clojure ist eine moderne, fortgeschrittene funktionale Programmiersprache, die sich an der Lisp/Scheme-Syntax orientiert. Clojure ist als Programmiersprache hauptsächlich für die Ausführungsumgebung der Java Virtual Machine gedacht. Der Clojure-Compiler erzeugt dementsprechend JVM-Bytecode. Obgleich bei funktionalen Sprachen wie Clojure Rekursion ein bevorzugtes Ausdrucksmittel zur Formulierung von Algorithmen ist, muss man in Clojure im Gegensatz zu anderen funktionalen Sprachen die Optimierung für Endrekursion aufgrund der Zielplattform JVM manuell vornehmen.
9.1.2.2.1.1 Fakultätsberechnung ohne “tail call elimination”
Der folgende Ausdruck definiert die neue Funktion fac, die die Fakultät rekursiv berechnet. So wie die Funktion hier definiert ist, erwartet sie zwei Parameter: \(n\) ist die “inverse Stufe” der Berechnung, \(acc\) ist der “Akkumulator”, also ein Parameter, der Aufruf für Aufruf die Ergebnisse der vorangegangenen Rekursionsstufen beinhaltet (dadurch wird der Rückgabewert als Aufrufparameter für die nächste Stufe repräsentiert).
Der Aufruf erfolgt z.B. für die Berechnung von \(20!\) durch (fac 4 1) (die 1 ist hier der Rückgabewert auf der letzten Stufe des Rekursionsankers). Da der Rekursionsanker \(n=1\) noch nicht erreicht ist, ist das Ergebnis (fac (- 4 1) (* 1 4)). Das geht immer so weiter, bis der Rekursionanker erreicht ist: (fac (- 2 1) (* 12 2)) \(ţo\) 24.
Die Werte der Fakultätsfunktion wachsen schnell zu sehr großen Zahlen, die nicht mehr mit einfachen Typen wie int repräsentiert werden können. Clojure kennt für solche Fälle den Typ bigint für ganze Zahlen beliebiger Länge (verknüpft mit Java’s BigInteger). Bei folgendem Aufruf der oben definierten Fakultätsfunktion auf bigint Werten ist das Resultat aber trotzdem nicht berechenbar, da die Schachtelung der Aufrufe die maximale Größe des Stacks sprengt:
9.1.2.2.1.2 Fakultätsberechnung mit manueller “tail call elimination”
Diese Defintion der Fakultätsberechnung ist jedoch endrekursiv, denn der letzte Schritt auf jeder Stufe ist immer der Rekursionsschritt. In diesem Fall ist es nicht erforderlich, die Ergebnisse der vorigen Stufen auf dem Stack zwischenzuspeichern. Stattdessen können die “neuen” Werte von \(n\) und \(acc\) direkt an die Speicherstelle der alten Werte auf dem Stack geschrieben werden. Damit ist die Endrekursion eliminiert und der Callstack wächst nicht mehr mit der Anzahl der Rekursionsstufen. Die maximale Größe des Stacks ist daher auch nicht mehr der limitierende Faktor bei der Berechnung der Fakultätsfuntion.
In Clojure gibt es zur Eliminierung der Endrekursion das “Special Form” recur. Es erwartet genausoviele Aufrufparameter wie die aufrufende Funktion hat. Die Bedeutung von recur ist, dass die Parameter von recur die Parameter der aufrufenden Funktion (hier der rekursive Aufruf von fac auf der Ebene darüber) in der recur übergebenen Reihenfolge ersetzt.
In der folgenden modifizierten Fassung von fac ersetzt (recur (- n 1) (* acc n)) den Rekursionsschritt (fac (- n 1) (* acc n)) durch die Endrekursions-optimierte Version.
Daher liefert die erneute Anwendung von (fac (bigint 4523) 1) keinen StackOverflowError, sondern eine sehr lange bigint-Zahl.
9.1.3 Coroutine
- auch ein “Unterprogramm”
- ist unterbrechbar an bestimmten Punkten
- in der Regel erfolgt der Aufruf einer anderen Coroutine
- nach Unterbrechung geht es direkt nach dem Unterbrechungspunkt der aufrufenden Coroutine weiter
- lokale Variablen und Aufrufparameter der aufrufenden Coroutine sind nach Unterbrechung wieder mit ihren ursprünglichen Werten verfügbar
- Coroutinen müssen deshalb ihren eigenen Kontext in der Regel über einen eigenen Call Stack verwalten (denn sie könnten selber wieder Subroutinen aufrufen, deren Aufrufparameter/Rückgabewerte auf einem Call Stack gespeichert werden müssen)
- Unterbrechungspunkt: in vielen Programmiersprachen
call-with-current-continuation(oft abgekürzt alscall/cc) oderyield(als Schlüsselwort oder Funktion/Methode)
Achtung: Bedeutung vonyieldin Java anders!
Das hat erstmal nichts mit paralleler Programmierung zu tun!
9.1.3.1 Beispiel in Modula-2
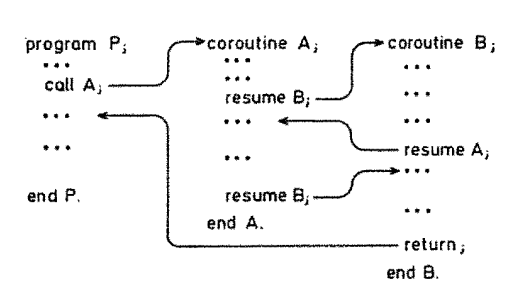
- Modula-2
- beispielhafter Kontrollfluss
- zwei Coroutinen:
AundB - rufen sich gegenseitig auf
- zwei Coroutinen:
9.1.4 Fiber
- Coroutinen mit kooperativem Multitasking
- nach der Unterbrechung wird nicht zu einer vom Aufrufer bestimmten Coroutine gesprungen, sondern ein Scheduler bestimmt zu welcher Coroutine als nächstes
- dieser Scheduler muss ein eigener sein, also unabhängig vom Scheduler des Betriebssystems, der zwischen Threads wechselt
- nebenläufige Code-Teile werden jeweils in eigene Coroutinen verschoben, die selbst bestimmen, an welchen Stellen sie unetrbrochen werden
Das ist Nebenläufigkeit ohne Parallelität!
- daher: implizite Synchronisation vorhanden
- kein gegenseitiger Ausschluss für konkurrierenden Zugriff auf gemeinsame Variablen erforderlich!
- aber: Blockierung kann durch I/O passieren.
- in dem Fall:
yieldzum Scheduler wünschenswert
- in dem Fall:
9.1.5 Vergleich Fiber mit Subroutine
9.1.5.1 Subroutine
- Unterprogramm
- kann geschachtelte Unteraufrufe von Subroutinen beinhalten
- wird grundsätzlich immer am Anfang begonnen
- wird immer “zum Ende” verlassen (bei jedem
return) - Kontext wird auf Call Stack des Aufrufer-Threads gespeichert
9.1.5.2 Coroutinen/Fibers
- Unterprogramm
- kann geschachtelte Unteraufrufe von Subroutinen beinhalten
- erster Aufruf am Anfang, danach weiterarbeiten am Punkt des letzten Verlassens
- kann an unterschiedlichen Punkten unterbrochen werden (
yield) - jede Coroutine benötigt eine eigene Verwaltung ihres Kontexts
9.1.6 Vergleich mit Threads
9.1.6.1 Threads
- Nebenläufige Programmteile
- Zugriff auf geteilte Variablen im Heap
- eigener Stack, threadlokale Variablen
- Scheduling deligiert an Betriebssystem
- mglw. parallele Ausführung (wenn es mehrere CPU’s gibt)
- Koordination konkurrierenden Zugriffs auf Speicher erforderlich (da Inkonsistenzen bei nicht-atomaren Zugriffen drohen) \(\to\)
synchronized, Locks, Atomics
9.1.6.2 Coroutinen/Fibers
- Nebenläufige Programmteile
- Zugriff auf geteilte Variablen im Heap
- eigener Stack, Fiber-lokale Variablen
- durch Anweisung kontrolliertier Wechsel zwischen Kontexten
- Ausführung mehrer Kontexte im selben Thread
- Koordination konkurrierenden Zugriffs auf Speicher nicht erforderlich, da Wechsel zwischen Kontexten nur an gewollten Punkten möglich \(\to\) implizite Synchronisation
Anmerkung: Damit synchronisationsfreie konkurrierende Zugriffe auf geteilten Speicher bei Fibers funktionieren, muss man aber darauf achten, keine “Transaktionen” auf Heap-Variablen durch Kontextwechsel zu unterbrechen. Die Kontextwechsel dürfen nur außerhalb von solchen kritischen Regionen eingefügt werden.
9.2 Umsetzung in Dart2
9.2.1 Dart Future
… liefert folgende Ausgabe3 …
1
2
3
4711
4
5
6- Dart Future: Wert (oder Fehler), der asynchron berechnet wird
asyncundawaitSchlüsselworteFuture.delayederzeugt ein (Dart-) Future, das nach einer vorgegebenen Verzögerung läuft.Future.value(...)führt...asynchron aus
Verkettung wie bei Completable Future:
9.2.2 Streams
- asynchrones
Iterable - Generator Function mit Schlüsselwort
async* - nach jedem
next()ist Wechsel zur nächsten Fiber (z.B. eine andere Generator Function) möglich
Stream<int> timedCounter(Duration interval, [int? maxCount]) async* {
int i = 0;
while (true) {
await Future.delayed(interval);
yield i++;
if (i == maxCount) break;
}
}
Stream<T> streamFromFutures<T>(Iterable<Future<T>> futures) async* {
for (final future in futures) {
var result = await future;
yield result;
}
}9.2.3 asynchrone I/O
Ähnlich wie bei Node.js gibt es eine zentrale Ereignis-Warteschlange, die zyklisch geupdated wird.
Alle I/O-Operationen sind asynchron:
import 'dart:convert';
import 'dart:io';
Future<void> main() async {
final process = await Process.start('ls', ['-l']);
final lineStream = process.stdout
.transform(const Utf8Decoder())
.transform(const LineSplitter());
await for (final line in lineStream) {
print(line);
}
await process.stderr.drain();
print('exit code: ${await process.exitCode}');
}9.3 Umsetzung in Java
9.3.1 Project Loom
- OpenJDK 20 enthält Project Loom, teils noch als Preview-Feature
- einige Neuerungen, u.a.
- Thread Builder API
- zentral und ganz tief in der JVM: Continuation ermöglicht Coroutinen
9.3.1.1 Virtual Threads
- a.k.a. Fibers
- aber etwas anders: Continuation wird in einem Threadpool ausgeführt
- frühere (inoffizielle) JVM-Umbauten bspw. Apache Commobs Javaflow4
- “klassische” Threads heißen nun “Kernel Thread” oder “Platform Thread”
- verspricht sehr wenig Overhead
- ermöglicht sehr viele Virtual Threads
- geringe Spawn-Zeitdauer
- im Moment aber noch entäuschende Start-Up Zeiten (Flaschenhals: Threadpool)
9.3.1.2 Structured Concurrency
- Aufspalten und Vereinigen innerhalb eines Code-Blocks
- soll Virtual Threads nutzen, um “massenhafte Nutzung” zu erlauben
- soll 1:1-Modellierung der Parallelität der Domäne ermöglichen
- u.a.
StructuredTaskScope- ähnlich einem
Executor - enthält
ThreadFactory - zum leichten Umsetzen von UML-Fork/-join
- ähnlich einem

9.3.2 StructuredTaskScope

9.3.3 Thread Builder API
- Erzeugen aller Threadarten ab jetzt mit Factories
Runnable runnable = () -> System.out.println(Thread.currentThread());
var virtualThreadFactory = Thread.Builder.Virtual.factory();
var kernelThreadFactory = Thread.Builder.factory();
var virtualThread = virtualThreadFactory.newThread(runnable);
var kernelThread = kernelThreadFactory.newThread(runnable);
virtualThread.start();
kernelThread.start();- u.a.
Executors.defaultThreadFactory()
Anwendung des Builder Patterns:
ofVirtual()liefertThread.Builder.OfVirtual- ein Builder
nameetc. liefern jeweils wieder Builder- keine Methode für Priority
unstarted()liefert dannThread(quasi build-Methode)- daran kann man
start()aufrufen
start(runnable)liefertThread(ebenfalls build-Methode)
Thread.Builder.OfPlatformist Builder für konventionelle Threads